By Judy Siegel-Itzkovich
Industry standards to help improve communication, repeatability and reproducibility of future high-throughput genomic sequencing findings have been proposed by George Washington University and US Food and Drug Administration (FDA) researchers.
Writing in PLOS Biology, they described a standardized communication method for researchers performing high-throughput sequencing (HTS) called BioCompute. They also called for big data infrastructure to support the future of personalized medicine.

Lead author Dr. Raja Mazumder, an associate professor of biochemistry and molecular medicine at the GW School of Medicine and Health Sciences in Washington, D.C., and colleagues call for a big data environment where genomic findings are robust and reproducible, and experimental data captured adheres to findable, accessible, interoperable, and reusable guiding principles.
The team collaborated on the BioCompute Object Specification Project, which enables standardized reporting of genomic sequence data provenance, including provenance domain, usability domain, execution domain, verification kit and error domain. This project includes a framework, which facilitates communication and promotes interoperability, using a standard that is freely accessible as a GitHub organization.
The authors wrote that the price of HTS decreased from $20 per base in 1990 to less than $0.01 per base in 2011. “Lower costs and greater accessibility resulted in a proliferation of data and corresponding analyses that in turn advanced the field of bioinformatics,” they noted. “Novel drug development and precision medicine research stand to benefit from innovative, reliable, and accurate -omics-based (i.e., genomics, transcriptomics, proteomics) investigation. However, the availability of HTS has outpaced existing practices for reporting on the protocols used in data analysis.”
“Without an infrastructure like the BioCompute Object, we will create silos of unusable data, making building upon this research more difficult,” said Mazumder. “We hope creating a standard now will clear this potential bottleneck.”
“Without standards or infrastructure around this new technology, we are left with a poor foundation for future work,” concluded Mazumder. “Instead of focusing on new discovery, we will be burdened with inefficiencies. Robust and reproducible data analysis is key to the future of personalized medicine, which is why we need to create a standard moving forward.”
iReceptor Plus Coordinator, Prof. Gur Yaari of the Faculty of Engineering at Bar-Ilan University in Ramat Gan, Israel, noted that “recurrent themes in bio-medical research are communication, repeatability, and reproducibility. These themes are of major concern to funding agencies and health systems, as they lay the foundations for the development of new drugs, therapeutics and diagnosis approaches and personalized medicine in general.”
He added that in the article mentioned above, the researchers expressed the critical need for industry standards to help improve these crucial aspects of modern bio-medical research.
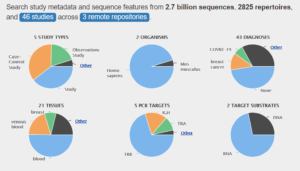
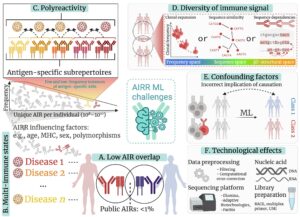
“Such standards will assist iReceptor Plus in deciding upon a robust strategy to store, analyze and share immune related high throughput data. Moreover, since AIRR-seq data have unique features that make repeatability, and reproducibility even more challenging, iReceptor Plus will build upon the standards that are constantly developed in the AIRR community, and eventually may contribute to the standardization of high-throughput genomic sequencing in general.”