By Judy Siegel-Itzkovich
With the COVID-19 pandemic challenging research teams around the world to find treatment and even an effective vaccine to help save humanity from disease and death, the iReceptor Plus Consortium (iR+) is, fortunately, in place to assist them in the exchange of vital data.
The Consortium is a European-Canadian collaborative project that brings together 19 partners from Europe, Canada, and the US whose mission is to develop means to store, share and analyze Adaptive Immune Receptor Repertoire sequencing (AIRR-seq) data. These data are produced when researchers and clinicians sequence antibody/B-cell and T-cell molecules using high-throughput technologies, and are critical to development of all novel immunotherapies, including vaccines.
The iReceptor Plus consortium works closely with the AIRR Community, which is a grass-roots group of immunologists, bioinformaticists, computer scientists, experts in legal, ethical and intellectual property issues who are developing guidelines and standards for the generation, annotation and storage of high-throughput AIRR-seq data to facilitate its use by the larger research community. iR+ follows these guidelines and provides a Data Commons for this data sharing community.
 Emeritus Prof. Felix Breden, an expert in ecology and evolutionary biology, population genetics and genomics at Simon Fraser University in British Columbia, Canada, recently discussed the challenge of the new coronavirus pandemic and how the AIRR sequencing data being amassed by the consortium is helping to find a solution. Breden was chair of the AIRR Community executive sub-committee since 2015 when he helped found the Community with Jamie Scott. He is active in the AIRR Community’s Common Repository Working Group and continues to serve as the Scientific Manager of the iReceptor Plus Consortium.
Emeritus Prof. Felix Breden, an expert in ecology and evolutionary biology, population genetics and genomics at Simon Fraser University in British Columbia, Canada, recently discussed the challenge of the new coronavirus pandemic and how the AIRR sequencing data being amassed by the consortium is helping to find a solution. Breden was chair of the AIRR Community executive sub-committee since 2015 when he helped found the Community with Jamie Scott. He is active in the AIRR Community’s Common Repository Working Group and continues to serve as the Scientific Manager of the iReceptor Plus Consortium.
Unique Data and Unique Challenges
Many groups from around the world are sequencing millions of receptor molecules from individuals with different responses to infection by SARS-CoV-2, the virus causing COVID-19.
For example, Microsoft and Adaptive Biotechnologies are collecting anonymous blood samples from people diagnosed with COVID-19, and are seeking to understand how the human immune system responds to the virus and why some patients become critically ill from the infectious disease while others are asymptomatic.
The research findings are being shared through an open-access dataset so researchers around the world can use it to maximum advantage for the development of better treatments for COVID-19.
The unique goal of iReceptor Gateway and the iR+ Consortium is to integrate results from all of the studies of COVID-19 patients, including those from the Microsoft/Adaptive Biotechnologies collaboration, so that results from many labs and institutions can be easily compared to each other on one bioinformatic platform. At present researchers can logon to the iReceptor Gateway and compare, analyze and download results from almost 700 Million sequences from nine COVID-19 studies, and the number of studies available through the Gateway increases every week.
The ability to share AIRR-seq data among research labs and across institutions greatly increases the value of each study. The data integration through iR+ provides increases sample sizes, greater statistical power and allows comparisons among affected patients, healthy controls and multiple disease states.

In addition, the iR+ Consortium is developing artificial intelligence approaches to try to predict which patients will develop severe COVID-19 versus remain assymptomatic, and whether vaccines will have to be tailored to specific geographic populations. Such artificial intelligence approaches require immense sample sizes to produce meaningful results, and such sample sizes are only possible by integrating data from multiple studies and multiple institutions. This is one of the ways the iReceptor Gateway and iR+ Consortium are unique.
“Many research groups are establishing new genomics and health databases, and funding agencies are not going to be able to pay the costs of all of them,” Breden stated. “AIRR-seq data are unique and demand a new type of data base and analysis tools.”
In order to produce the huge diversity, necessary to detect all possible pathogens, most vertebrate genomes, including humans, recombine pieces of immunoglobulin genes and T-cell receptor genes to produce the adaptive immune system. This molecular genetic mechanism is unique to these genes, no other genes in the genome recombine like this, and therefore curating and analyzing these receptor repertoires demand unique databases and analysis tools.
That is why the AIRR Community was founded, and why the iReceptor Gateway and the iR+ Consortium has worked so hard to provide a means for storing and analyzing these data. By integrating data from the adaptive immune system from multiple studies, we can facilitate the development of new immune therapies such as vaccines, monoclonal antibodies against autoimmune diseases, and novel cancer immunotherapies that are designed to turn the immune system against the cancerous growth.
For example, this diversity mechanism is essential to the natural response to infections and to how vaccines work. If someone gets infected by SARS-Cov-2, the virus causing COVID-19, antibodies and the immune system come into play. “If she has antibodies that bind well to the virus, the body selects the cells producing these good binders, lets them expand and then mutates the cells. In the next round of selection, antibodies that are even-better binders are selected, expanded and mutated,” explained Breden. “This process of selection and mutation usually produces a good adaptive response in the individual even if the body has not seen that pathogen before.
Genes evolve in an individual to give a response to new pathogens, and that is why it is called the adaptive immune system. Only in this way can we produce the diversity to respond to a huge array of pathogens, even novel ones such as the novel coronavirus.
A vaccine is a molecule designed to induce this adaptive antibody in individuals who have never seen this pathogen, speeding up their response when challenged by the pathogen. The system has to be immensely variable to not only recognize pathogens, but to tell them apart from thousands of “self” molecules that cannot be attacked in this way.
Breden added that all of these reasons point to why the Data Commons for the AIRR Community, provided by the iReceptor Gateway and the iR+ Consortium, is such an important and difficult undertaking.
Each individual has millions of B-cell and T-cell receptors at any one time. Where we used to sequence only a few hundred receptors in a study, perhaps before and after a vaccine trial, or at several points in an autoimmune disease, now we sequence millions of sequences at each time point.
Even so, we are only sampling a small portion of all of the variability that an individual has to fight off pathogens in the environment. Each database in the AIRR Data Commons stores these sequences according to the AIRR standards, and then these can be queried through the iReceptor Gateway.
We can’t describe the full repertoire from any individual, but by putting repertoires from many individuals from many diseases together in one system, we can describe the response of the adaptive immune system to diseases in exquisite detail, which will lead to new understanding, and new therapies and diagnostics.
2.8 Billion Sequence Annotations
The iReceptor Gateway, which integrates data from multiple repositories, is a public archive with more than 40 studies. It currently stores 2,733 repertoires. There can even be multiple repertoires per person, for example, examining a person’s immune response before and after a vaccination in a clinical trial, or at multiple time points during the development of a disease.
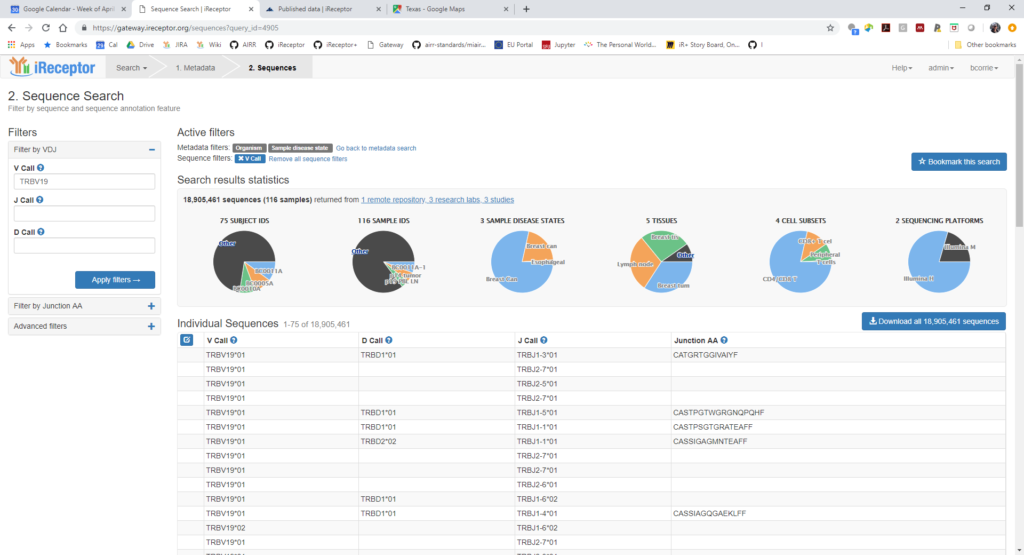
If you didn’t have such a Gateway for sharing data in a common format, you’d have to contact each researcher and work out how to compare data from each study individually, said Breden. “But with the iReceptor Gateway, a researcher can issue the same query command and send this to all the different repositories. Because they share standards, the researcher can ask for if each repository has any HIV data, for example, on women over 40. You just issue the same command to each repository; you don’t have to change the search. That is unique. In this way we make it easy to compare 2.8 billion sequences from different studies, and this is expanding quickly.”
This sounds like a lot, he continued, but just one cancer study can produce 500 million receptor sequences. “We are not capturing enough yet; there is so much more work to do. But nobody else has a place where one can share and compare AIRR-seq data sets, where you get data from all these studies to compare at once. Again, without these standards researchers would probably upload the raw data to a public data base, and other researchers would have to download the data and manually figure out which came from which samples. This is a very unusable system. Nobody else has put such data together in common format. There are other AIRR-seq databases that are not open to the public and that don’t have as many sequences. The iR+ Consortium is trying to integrate all of these into one big system very soon.
The iReceptor Platform
Currently, most AIRR-seq data are stored and curated by individual labs, using a variety of tools and technologies. The innovative iR+ platform will lower the barrier to access and analyze large AIRR-seq datasets which will ease the availability of these important data to academia, industry and clinical partners.
Defeating the coronavirus pandemic will require unprecedented cooperation from the researchers around the globe. The AIRR Community recently made a call upon its members and the wider research community to share experiences, resources, samples and data as openly and freely as possible, and to work within their respective systems to break down barriers to achieve this goal, subject to the guiding principles of respect, privacy and protection for patients and all people.
The project will facilitate the search for a totally new class of biomarkers to support novel treatments, based on patterns in the AIRR-seq repertoires. The ability to share and compare AIRR-seq data will also promote the discovery of biomedical interventions that manipulate the adaptive immune system such as vaccines and other immunotherapies.
The repository has accumulated much data from COVID 19 patients around the world. “Researchers are contacting iReceptor Plus to ask to share data through our gateway. We have seven COVID-19 datasets already. One is from China, and others are from northern Europe and America. There will be one from South Korea.” Currently, the repositories are in Vancouver, Canada and Dallas, Texas. There will soon be another at the Sorbonne in Paris.
In September of this year, the AIRR Community will join many partners of IReceptor Plus and hold a three-day conference on COVID-19 data that is certain to be very beneficial, he predicted. The conference is open to all researchers interested in AIRR-seq data and COVID-19 research. For more information.